

代码拉取完成,页面将自动刷新
同步操作将从 cungudafa/keras-yolo3 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
参考博客:
【Yolo3】一文掌握图像标注、训练、识别(Keras+TensorFlow-gpu)
【Keras+TensorFlow+Yolo3】教你如何识别影视剧人手模型
环境:windows10 + anaconda3(conda4.8.2)+ labelImg1.8.1 + VSCode
版本:python3.6.0 + opencv4.1.0 + yolo3 +keras 2.3.1 +tensorflow-gpu2.1.0
环境安装记录:
【GPU】win10 (1050Ti)+anaconda3+python3.6+CUDA10.0+tensorflow-gpu2.1.0
库:numpy1.18.2、Pillow7.0.0、matplotlib 、python-opencv4.2.0
原始目录:docs/tree_old.txt
我重新整合了一下目录结构:docs/tree.txt
下载项目框架
git clone https://gitee.com/cungudafa/keras-yolo3.git
下载权重
单独下载yolov3.weights 权重,放在项目根目录下
将 DarkNet 的.weights文件转换成 Keras 的.h5文件
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5
可以查看到我们的模型结构: docs/model_summary.txt
下载数据集:(我这里用hand进行试验,你可以用你自己的标注数据集)
本次使用的数据集来自:牛津大学Arpit Mittal, Andrew Zisserman和 Phil Torr

资料下载:
我们用到的数据集为VOC格式:我们仅下载evaluation_code.tar.gz(13.8M)即可。
将下载的数据集复制到项目路径下:(事实是数据集有400+图片,我训练起来太累了,容易过拟合,这里只用了009985-010028共40+张图片进行训练)
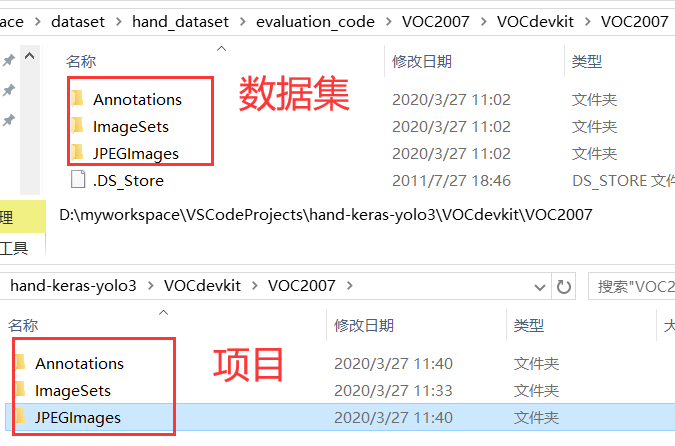
运行script目录下获取标签:
voc标签格式:voc_annotation.py
yolo标签格式:yolo_annotation.py
修改train.py中训练轮速、路径(可选步骤)
训练 train.py(50轮和100轮,各保存一次)保存在logs目录下
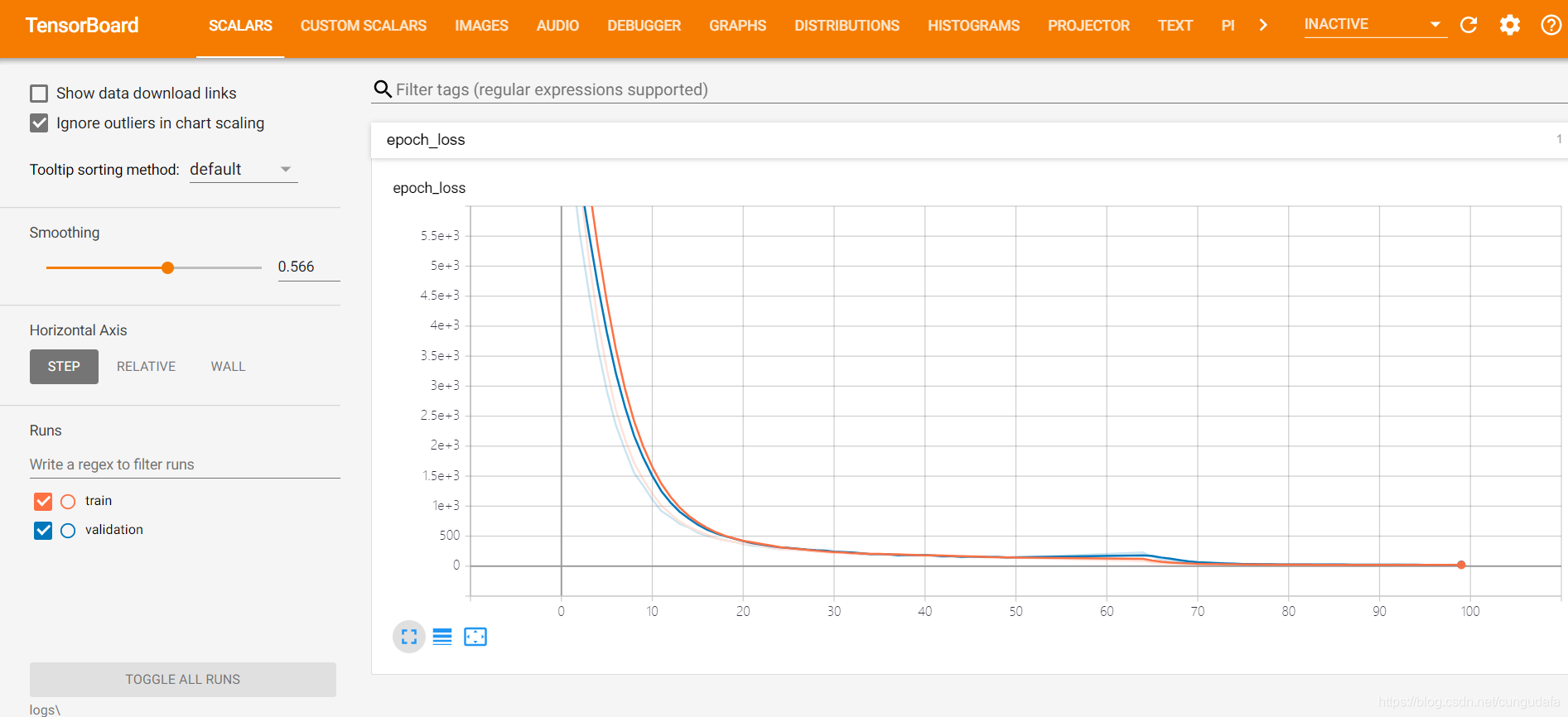
神经网络可视化,在根目录下运行:
tensorboard --logdir=logs\会将运行记录打印到浏览器中
打开浏览器查看:http://localhost:6006/
可视化查看神经网络loss:
项目目录下运行:
tensorboard --logdir=logs\
浏览器查看:http://localhost:6006/
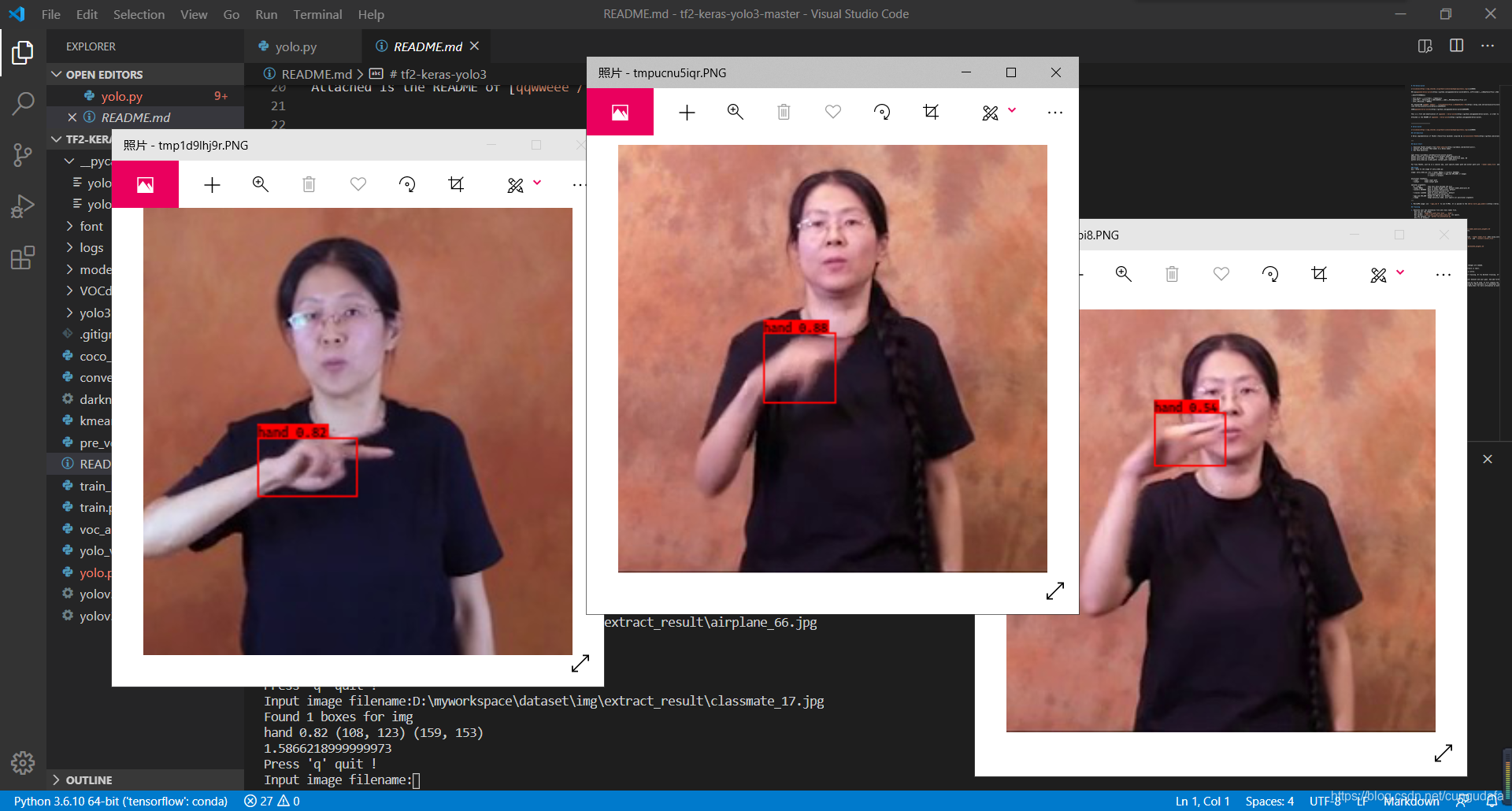
参考tf2-keras-yolo3,可以直接对图片和视频进行检测。
我另外封装了一下检测部分的代码:识别部分keras-yolo3-recognize
运行predict.py或者:
# 图片检测
python yolo_video.py --image
再输入图片路径
# 视频检测
python yolo_video.py --input img\test.mp4


此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





