代码拉取完成,页面将自动刷新
现在市面上有各种大型的搜索引擎
比如:谷歌、bing、百度
这些大型的搜索引擎,需要把全网的所有网页信息给抓取下来
并且需要把数据进行保存,并建立相应的后端索引模块
后续需要根据用输入的关键字,对数据进行排序,来设置网页显示优先级
还包含了网页和网页之间关联度的问题
所以我们自己是不可能实现这些大型搜索引擎的
我们可以做的就是站内搜索
因为站内搜索搜索的数据更垂直具有很强的相关性,数据量更小
这就意味着我们保存和建立索引的工作量是更小的
我们通过实现一个站内的搜索引擎,以此达到管中窥豹的效果
去揣测别人的大型搜索引擎大概是怎么做的
刚好boost的官网是没有站内搜索,所以我们可以自己去实现一个
对于我们自己实现的搜索引擎的展现结果是怎么样的,我们在实现之前需要进行明确
我们以美食作为搜索的关键词分别向谷歌、bing、百度进行搜索

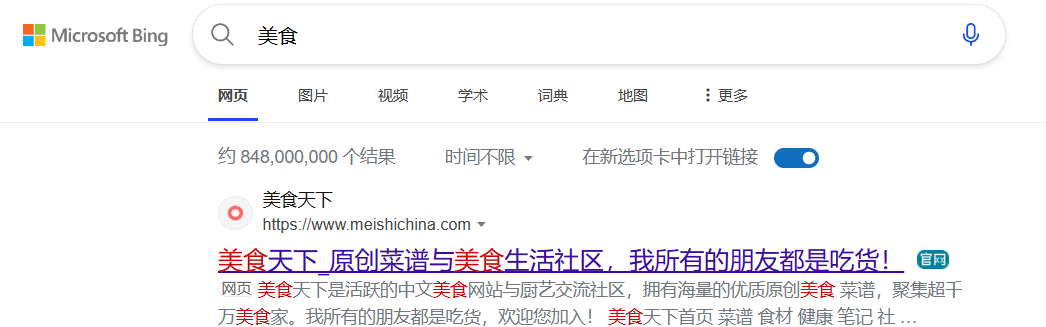
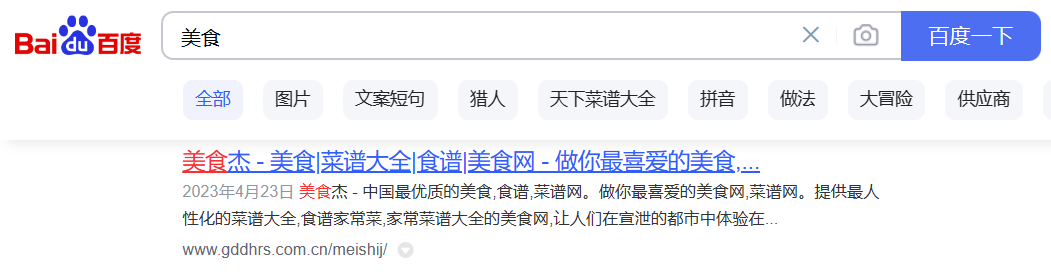
通过以上的搜索我们可以的得知,搜索引擎的大部分展现搜索结果都是由三个部分构成
所以也明确了我们自己实现的搜索引擎以什么样的形式展示搜索的结果了
然后通过点击title的方式,跳转到目标网站
在开始项目之前,我们首先需要了解关于搜索引擎的相关的宏观原理
让我们在实现项目的时候不会对具体的实现步骤有太多的疑点
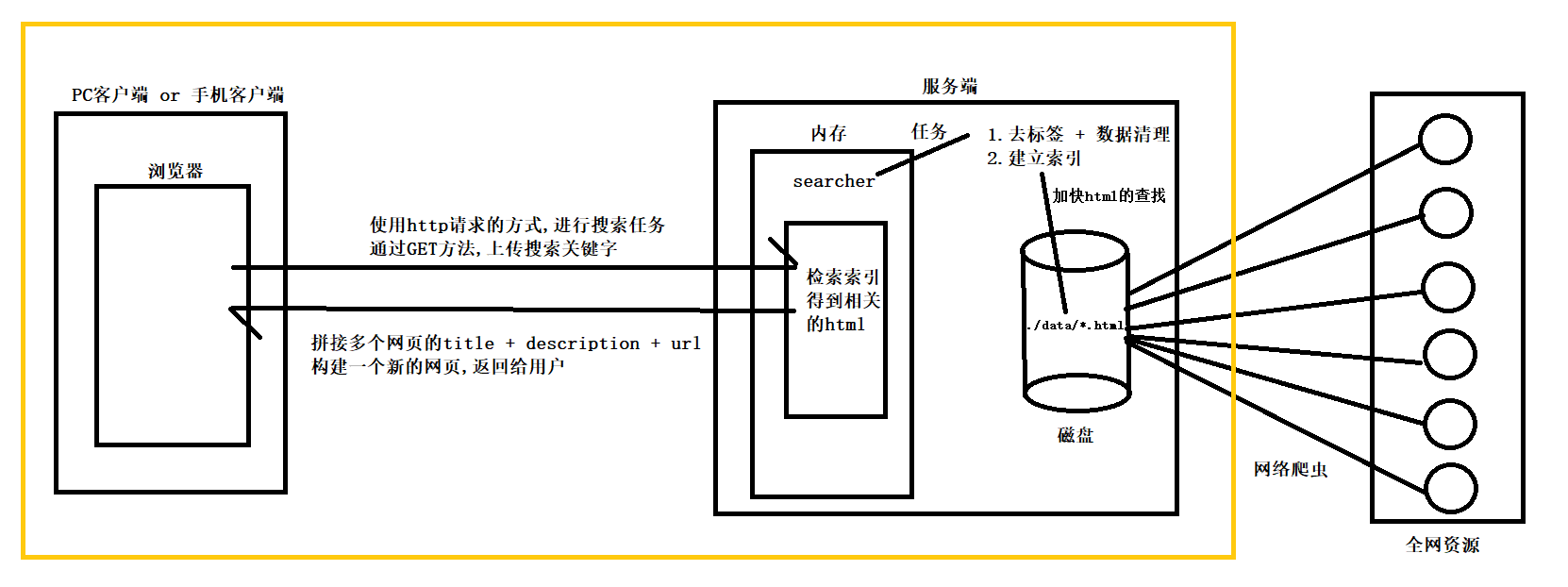
首先服务端会在各种网站当中,通过网络爬虫程序,抓取网页资源,放在对应的服务端特定目录的磁盘下
然后我们的searcher会对抓取来的网页资源做两步处理
接下来是客户端通过浏览器,使用http请求,进行搜索任务
而http请求当中是一定包含搜索关键字的
这个http请求通过get方法进行提交的,将搜索的关键字通过url传递给服务端
searcher通过得到的关键字,检索索引,得到相关的html
最后把搜索到的多个网页结果, 进行拼接,构建一个新的网页,返回给客户端
我们所实现的搜索引擎,会涵盖黄色框的中的部分
因为众所周知的原因,我们不去实现爬虫的部分,我们通过合法渠道把相关的网络资源进行下载
- 后端:C/C++、C++11、STL、准标准库Boost、Jsoncpp、cppjieba、cpp-httplib
- 前端:html5、css、js、jQuery、Ajax
- 项目环境:Centos 7.6云服务器、vim、gcc(g++)、Makefile、visual studio code
假设我们现在有两个文档
- 文档1:妈妈买了六斤小米
- 文档2:妈妈买了个小米手机
正排索引:就是从文档ID找到文档内容(文档中的关键字)
| 文档ID | 文档内容 |
|---|---|
| 1 | 妈妈买了六斤小米 |
| 2 | 妈妈买了个小米手机 |
当我们得到了目标文档内容之后,我们需要对文档进行分词
目的是为了方便建立倒排索引和方便进行查找
如下是我们分词的大致情况
- 文档1[妈妈买了六斤小米]:妈妈/买/六斤/小米/六斤小米
- 文档2[妈妈买了个小米手机]:妈妈/买/小米/手机/小米手机
我们可以发现,分词的时候有一些词我们不进行考虑,这种词我们叫做停止词
因为这些词出场频率太高了,如果我们把这些词也作为关键词,那么搜索的时候区分唯一性的价值不大,而且会增加我们建立索引的成本,从而增加我们搜索的成本
常见的停止词:了、个、的、吗、a、the......
倒排索引:根据文档内容进行分词,整理不重复的各个关键词,对应联系到具体的文档ID
| 关键词(唯一性) | 文档ID |
|---|---|
| 妈妈 | 文档1、文档2 |
| 买 | 文档1、文档2 |
| 六斤 | 文档1 |
| 小米 | 文档1、文档2 |
| 六斤小米 | 文档1 |
| 手机 | 文档2 |
| 小米手机 | 文档2 |
我们使用正排索引和倒排索引模拟一次查找的过程:
首先用户输入小米->我们利用倒排索引,将关键词用于查找->提取出文档ID是1和2->然后我们根据正排索引,找到文档中的内容->接着我们将文档中的内容进行摘要,形成title + description + url的形式->最后我们构建响应结果回去
这里有一个问题,如果我们根据关键字,找到了多个文档,那么我们应该怎么呈现给用户呢?
我们一般会根据文档和关键字之间的相关性,建立对应的公式,来计算当前的关键字对于各个文档的权值是多少,权值高的将优先展示给客户
parser
我们需要对数据进行去标签的处理,那么这些数据是哪来的?
我们进入boost的官网:https://www.boost.org
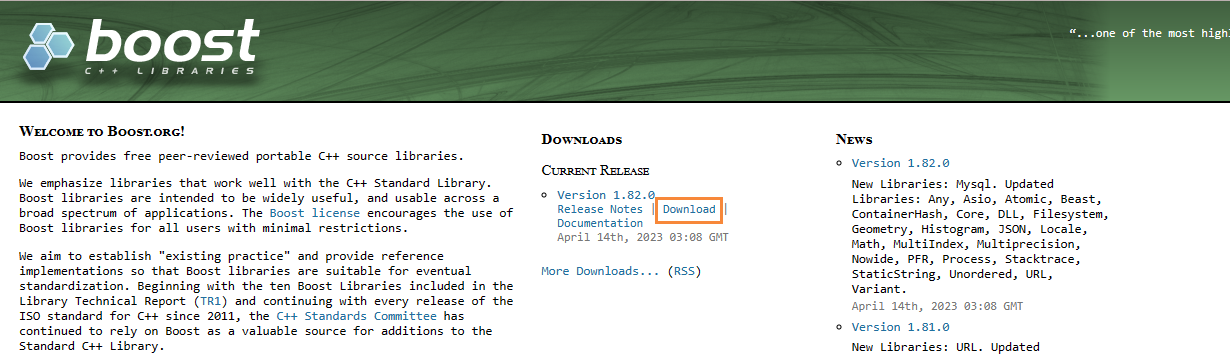
点击Download,下载最新版本的boost库文件,并进行解压
我们所需要的数据文件就是/boost_1_78_0/doc/*下的所有html文件
我们为什么需要对原始的网页数据进行去标签的操作?
我们随意展示一段html网页代码
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>What's Included in This Document</title>
<link rel="stylesheet" href="../../doc/src/boostbook.css" type="text/css">
<meta name="generator" content="DocBook XSL Stylesheets V1.79.1">
<link rel="home" href="index.html" title="The Boost C++ Libraries BoostBook Documentation Subset">
<link rel="up" href="index.html" title="The Boost C++ Libraries BoostBook Documentation Subset">
<link rel="prev" href="index.html" title="The Boost C++ Libraries BoostBook Documentation Subset">
<link rel="next" href="libraries.html" title="Part I. The Boost C++ Libraries (BoostBook Subset)">
</head>
<body bgcolor="white" text="black" link="#0000FF" vlink="#840084" alink="#0000FF">
<table cellpadding="2" width="100%">
<tr>
<td valign="top"><img alt="Boost C++ Libraries" width="277" height="86" src="../../boost.png"></td>
<td align="center"><a href="../../index.html">Home</a></td>
<td align="center"><a href="../../libs/libraries.htm">Libraries</a></td>
<td align="center"><a href="http://www.boost.org/users/people.html">People</a></td>
<td align="center"><a href="http://www.boost.org/users/faq.html">FAQ</a></td>
<td align="center"><a href="../../more/index.htm">More</a></td>
</tr>
</table>
<hr>
<div class="spirit-nav">
<a accesskey="p" href="index.html"><img src="../../doc/src/images/prev.png" alt="Prev"></a><a accesskey="u"
href="index.html"><img src="../../doc/src/images/up.png" alt="Up"></a><a accesskey="h"
href="index.html"><img src="../../doc/src/images/home.png" alt="Home"></a><a accesskey="n"
href="libraries.html"><img src="../../doc/src/images/next.png" alt="Next"></a>
</div>
<div class="preface">
<div class="titlepage">
<div>
<div>
<h1 class="title">
<a name="about"></a>What's Included in This Document
</h1>
</div>
</div>
</div>
<p>This document represents only a subset of the full Boost
documentation: that part which is generated from BoostBook or
QuickBook sources. Eventually all Boost libraries may use these
formats, but in the meantime, much of Boost's documentation is not
available here. Please
see <a href="http://www.boost.org/libs" target="_top">http://www.boost.org/libs</a>
for complete documentation.
</p>
<p>
Documentation for some of the libraries described in this document is
available in alternative formats:
</p>
<div class="itemizedlist">
<ul class="itemizedlist" style="list-style-type: disc; ">
<li class="listitem"><a class="link" href="index.html"
title="The Boost C++ Libraries BoostBook Documentation Subset">HTML</a></li>
</ul>
</div>
<p>
</p>
<div class="itemizedlist">
<ul class="itemizedlist" style="list-style-type: disc; ">
<li class="listitem"><a href="http://sourceforge.net/projects/boost/files/boost-docs/"
target="_top">PDF</a></li>
</ul>
</div>
<p>
</p>
</div>
<table xmlns:rev="http://www.cs.rpi.edu/~gregod/boost/tools/doc/revision" width="100%">
<tr>
<td align="left"></td>
<td align="right">
<div class="copyright-footer"></div>
</td>
</tr>
</table>
<hr>
<div class="spirit-nav">
<a accesskey="p" href="index.html"><img src="../../doc/src/images/prev.png" alt="Prev"></a><a accesskey="u"
href="index.html"><img src="../../doc/src/images/up.png" alt="Up"></a><a accesskey="h"
href="index.html"><img src="../../doc/src/images/home.png" alt="Home"></a><a accesskey="n"
href="libraries.html"><img src="../../doc/src/images/next.png" alt="Next"></a>
</div>
</body>
</html>
可以看到html有两种标签:
这些标签本身和里面的内容,对于我们进行搜索是没有价值的
当我们去掉这些标签之后,剩下的内容,才是我们搜索所需要的内容
建立存放boost原始的html文件和存放去标签之后的干净文件的目录
原始html文件路径:~/boost_search_engine/data/input
干净文件文件路径:~/boost_search_engine/raw_html
路径建立好之后,我们将/boost_1_78_0/doc/*下的所有html文件拷贝到原始html文件路径下
使用如下命令查看input目录下共有多少个文件
ls -Rl | grep -E '*.html' | wc -l
8141
我们parser的目标就是将这8141这个html文件都进行去标签,然后写入到同一个文件中
每个文件的内容不需要任何的\n,文档中title/content/url之间用\3区分
\3就是ASCII码为3的字符,其字符解释是正文结束
所以我们可以用来作为文档和文档之间的区分
这样做的原因是我们ASCII表分为控制字符和打印字符
\3属于是控制字符的一种,是不会显示在屏幕上
而我们的html文件内容,里面的字符都是属于ASCII打印字符,是会显示在屏幕上
这样就不会污染我们文档中的显示内容
类似于xxxxxxxxx\3yyyyyyyyy\3zzzzzzzzz\3
明白了数据的来源和parser的处理的基本原理,我们可以正式开始编写parser了
因为我们的parser需要对文件进行处理,但是C++的标准库对于文件处理的支持不太好
所以我们我们需要手动安装boost开发库
sudo yum install -y boost-devel
编写parser的过程中,我们到了解析html文件的一步时
我们需要了解整个html的大致结构和我们需要拿到哪一部分的数据
首先我们需要解析的是title,这个标签对在整个html文件中只会出现一对
我们需要做的就是提取橙色部分,舍去红色部分

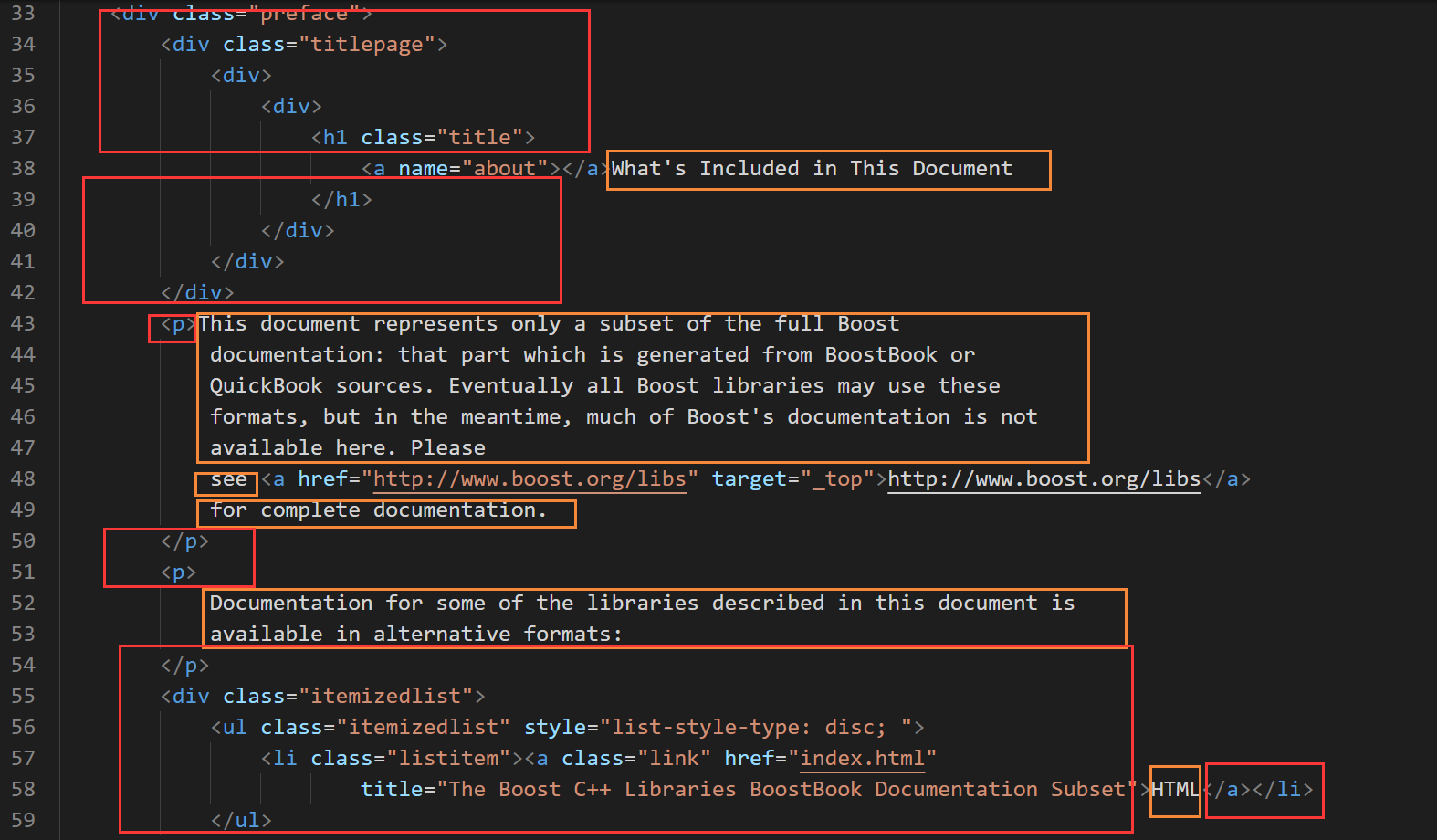
然后我们需要解析的是content,这一步的本质就是去标签
我们需要做的就是提取橙色部分,舍去红色部分
最后我们需要解析的是url
下面是booost官网的url样例
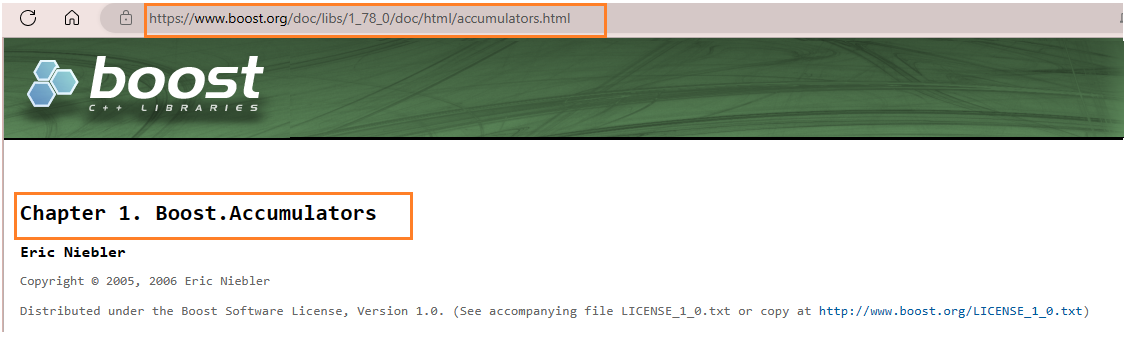
下面是我们下载下来的url样例(accumulators.html)

下面是我们把下载下来的boost库的样例拷贝到项目中的样例(accumulators.html)

我们可以具体观察他们之间的差距
通过固定的url前缀 + url后缀就能构建一个官网的连接
url前缀 : url_head = "https://www.boost.org/doc/libs/1_78_0/doc/html";
url后缀 : url_tail = data/input/accumulators.html -> url_tail = /accumulators.html;
官网连接 : url = url_head + url_tail;
最后我们拿到所有的网页解析内容,将其写入到文件中,路径是~/boost_search_engine/raw_html
之前我们说过一种网页和网页进行分割的一种方式是直接采用'\3'作为分割符的形式
但是我们我们把数据写入文件中,需要考虑下一次读取的时候,也方便操作
所以我们需要采用如下的分割方式
title/3content/3url \n title/3content/3url \n title/3content/3url \n
使用'\3'作为title和content和url的分隔符,使用'\n'作为网页与网页之间的分割符
这样方便我们使用getline(),获取到文档的全部内容
index
index的基本结构
我们需要明确的是我们需要建立正排索引和倒排索引
正排索引是根据id拿到内容的
所以我们使用如下结构代表正排索引
//正排索引的数据结构用数组,数组的下标天然是文档的ID std::vector<DocInfo> forward_index; //正排索引 struct DocInfo { std::string title; //文档的标题 std::string content; //文档对应的去标签之后的内容 std::string url; //官网文档url uint64_t doc_id; //文档的ID,容易方便倒排索引的建立 };倒排索引是根据关键字拿到id的
所以我们使用如下结构代表倒排索引
//倒排索引一定是一个关键字和一组(个)InvertedElem对应[关键字和倒排拉链的映射关系] std::unordered_map<std::string, InvertedList> inverted_index; struct InvertedElem { //文档的id,d uint64_t doc_id; //关键字 std::string word; //权值 int weight; }; //倒排拉链 typedef std::vector<InvertedElem> InvertedList;建立正排索引的具体步骤
我们拿到raw_html文件中的内容之后
对其进行解析,因为之前的parse对html的源文件进行了去标签的处理
同时对去掉标签后的数据,进行了一定的格式化处理
所以我们按照格式化的分割符('/3')对拿到的raw_html数据进行解析切分
然后将解析切分完毕的数据,再次填充到我们所定义的DocInfo结构中
这个解析的过程,我们使用boost库中的split进行内容的切分
注意其中的doc_id就是插入DocInfo到forward_index的下标
建立倒排索引的具体步骤
我们的倒排索引索引是需要根据正排索引的元素也就是DocInfo来建立的
同时倒排索引还需要将DocInfo里面的title和content进行分词的操作
所以我们这里使用cppjieba的分词库
下载地址是:https://github.com/yanyiwu/cppjieba.git
注意使用cppjieba还需要一个库就是cppjieba/deps/limonp
这个库是需要单独下载的
下载地址是:https://github.com/yanyiwu/limonp.git
同时我们需要注意,需要把limonp库放在include/cppjieba/下
进行完分词操作之后,我们需要对这些词进行词频统计
所以我们有如下的结构
struct word_cnt { title_cnt; content_cnt; } unordered_map<std::string, word_cnt> word_cnt;word_cnt是统计这个词在title和content出现的次数,也就是记录词频的
word_cnt是用来暂时保存词频的映射表
然后我们遍历word_cnt,对每一个词进行InvertedElem的建立
将建立好的InvertedElem插入到inverted_list中,形成一个关键词的倒排拉链
后续inverted_index可以根据同一个关键词找到同一个倒排拉链
PS:建立倒排索引的时候,要忽略大小写!!
searcher
- 当索引的模块建立编写好了,那么就可以进行搜索模块的准备了
在搜索模块中,我们利用编写好的索引模块,建立索引对象
使得每个词都有所对应的倒排拉链
我们搜索模块的目的,就是传入一个字符串的时候,将这个所有字符串进行进行jieba分词
然后获得所有的词的倒排拉链
我们把所有倒排拉链进行汇总,然后对倒排拉链里面的元素按照权值进行降序排列
然后根据倒排拉链里面的元素获得其在正排索引的位置
也就拿到了关于这个词的文档
最后我们根据拿到的文档,然后构建一个json字符串进行返回
这个字符串包含了这些所有词的文档
- 在编写完searcher模块后,我们经过测试,发现了一些问题
通过运行中的搜索程序,我们输入了split,然后返回了这个字符串所对应的倒排拉链,以json的形式返回的
我们挑选了一个weight为13的网页进行访问
但是可以看见,网页中的weight有4个,如果加上标题中的1个,那么理论上这个网页的weight的权值应该是15,那么为什么我们的权值是13呢?
PS:对整个文件进行去标签,其中是包括标签的 实际如果一个词在title中出现,一定会被当标题和当内容分别被统计一次
所有一个标签实际占用的权值是11
我们根据倒排元素中的doc_id找到了,这个文档的位置
其中橙色圈中的单词t因为我们去标签时候的特殊处理,导致多个词合成了一个词
所以可以看出这些词合grep出来的词是一致的,但是因为jieba分词的原因
多个词合成的词,jieba不能将他们进行拆分,所以split的数目就会减少
而且我们可以注意到,这里splitboost合成词,是标题词和其他词进行了合成
所以上面说的一个词在title中出现,一定会被当标题和当内容分别被统计一次
这里就不会当作内容词进行统计了
除掉了橙色圈中的词那么最后的权值就应该是13
所以出现上述权值和网页中的单词数量不匹配的原因就是
jeiba分词无法将合成词进行分词和内容去标签处理不够到位导致的
http_server
cpp-httplib库的引用
我们编写网络服务模块,需要使用到cpp-httplib库
下载地址如下:cpp-httplib
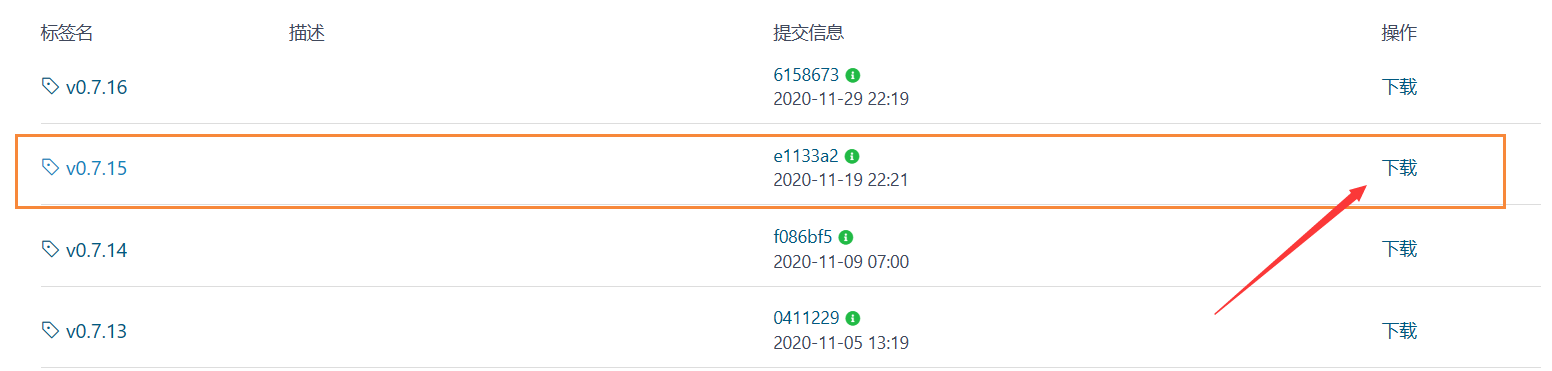
我们使用0.7.15的版本,这个版本相对稳定一点,如果是最新版本可能对编译的要求比较高
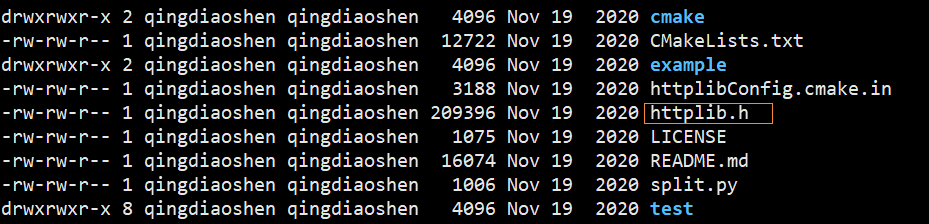
下载好压缩包,上传到服务器解压之后得到如下的文件,而我们主要使用的是httplib.h
使用cpp-httplib库的时候,需要较新版本的gcc编译器
用老的编译器,要么编译不通过,要么直接运行报错
我们centos 7默认gcc版本是4.8.5
gcc的升级
首先安装scl
sudo yum -y install centos-release-scl scl-utils-build然后安装新版本的gcc
sudo yum -y install devtoolset-7-gcc devtoolset-7-gcc-c++查看是否安装成功
使用命令进行新版本的启动
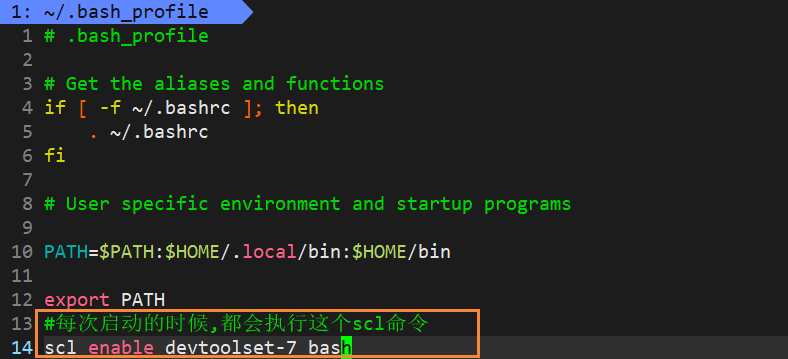
scl enable devtoolset-7 bash可以看到已经是7.3.1版本了
但是命令行启动只有在本次对话窗口有效,如果新启对话窗口,那么就还是原来的版本
如果不想每次都输入指令来启动新版本的gcc
可以在~/.bash_profile文件里面加入如下的指令
scl enable devtoolset-7 bash
在编写前端代码之前我们需要知道我们的网页的大致结构是什么样式的
在参考了一些所有引擎的页面之后,根据我现有的能力
我的设计大致如下
在编写前端代码的过程中,涉及到前后端进行交互的代码,需要使用JS进行编写
但是如果直接使用原生的JS进行编写成本太高了,所以我们这里条件使用JQuery
在网页html文件里面引入JQuery的链接,我们就可以直接进行使用
进行一通编写后,我们可以的如下的网页效果
到此位置,整个项目已经完成的差不多了
不过还存在一点点小问题,比如我们的搜索关键词为:
你是一个好人
经过jieba分词之后,形成你/是/一个/好人
如果一个文档中,都出现了这四个词,那么返回的搜索页面会出现重复的结果
所以我们做如下的测试
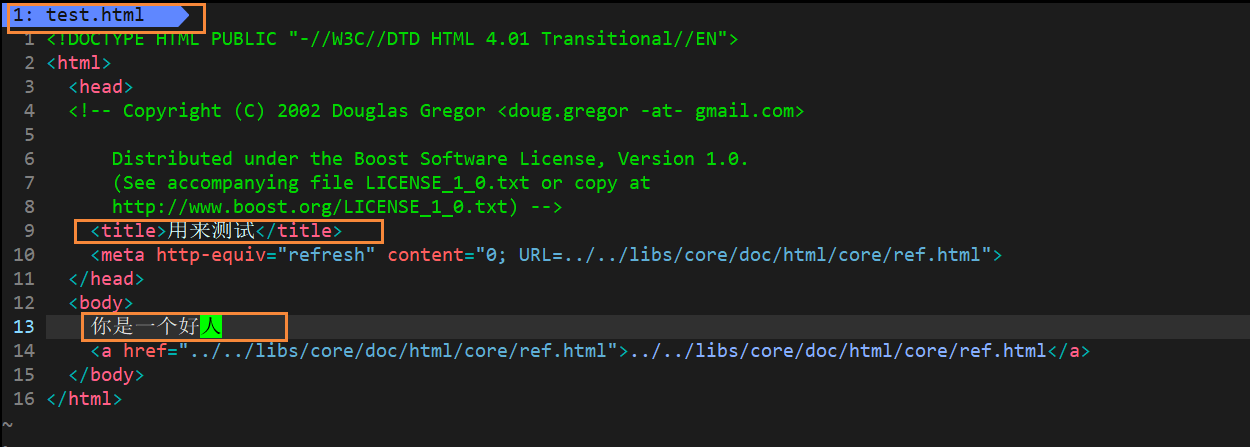
在项目的原始数据来源的文件夹中新增一个test.html
修改里面的文本内容为你是一个好人
因为是我们新增加的原始html数据
所以我们需要重新进行数据清理,重新执行parse模块
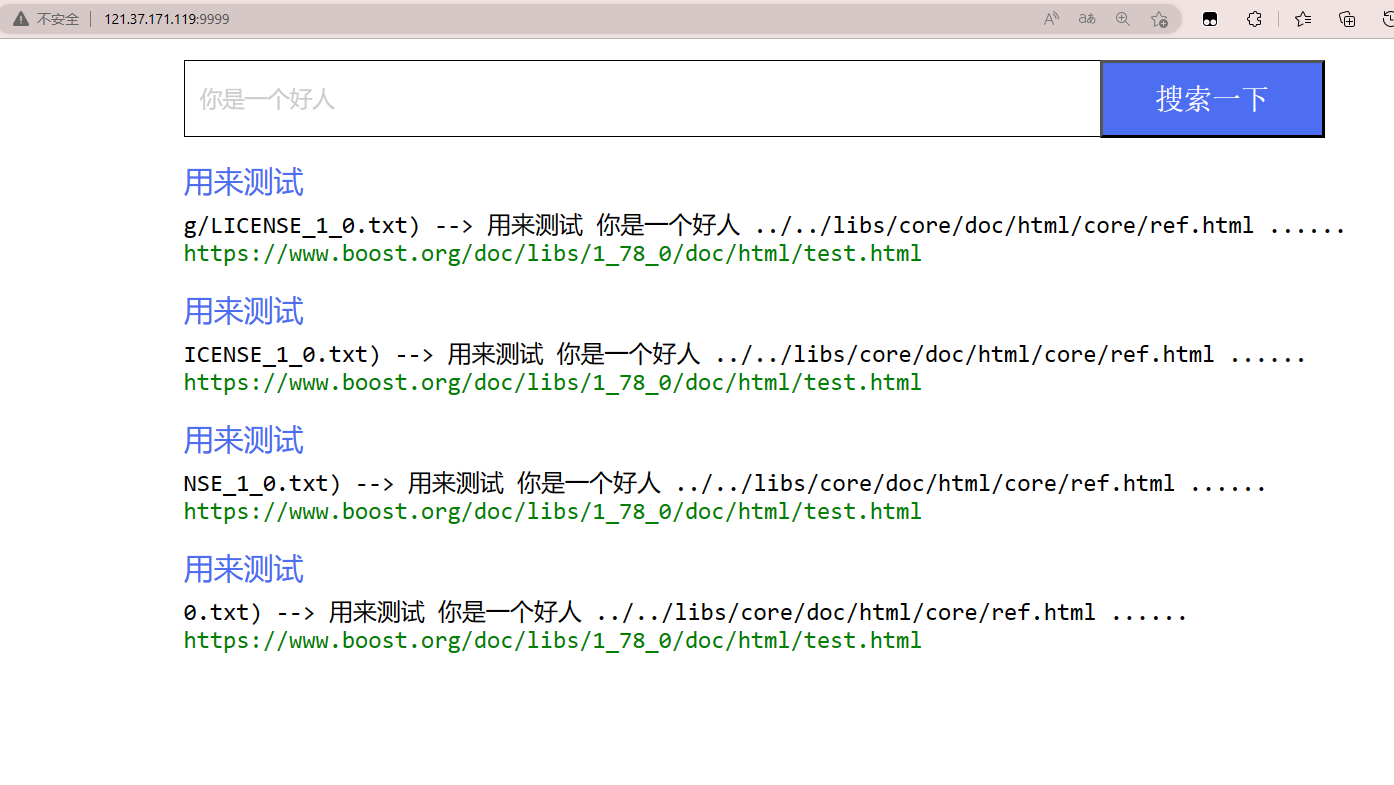
当我们搜索你是一个好人的时候,会重复出现一样的链接
所以我们需要对这些重复的搜索结果进行去重
在后端的搜索模块中我们根据关键字获得所有的倒排拉链
然后我们将倒排拉链里面的倒排元素进行去重
倒排元素如果有相同的id,就归为同一个
然后进行倒排元素权值的相加
最后呈现出来的结果如下
添加日志
增加一个日志,记录程序运行过程中的异常情况
效果如下
最后我们把这个服务部署到linux机器上,这样我们就可以随时随地的使用网站进行搜索了
使用如下命令进行服务的部署
nohup ./http_server > log.txt 2>&1 &把所有的日志信息都重定向到log.txt文件中
效果如下:
去掉暂停词
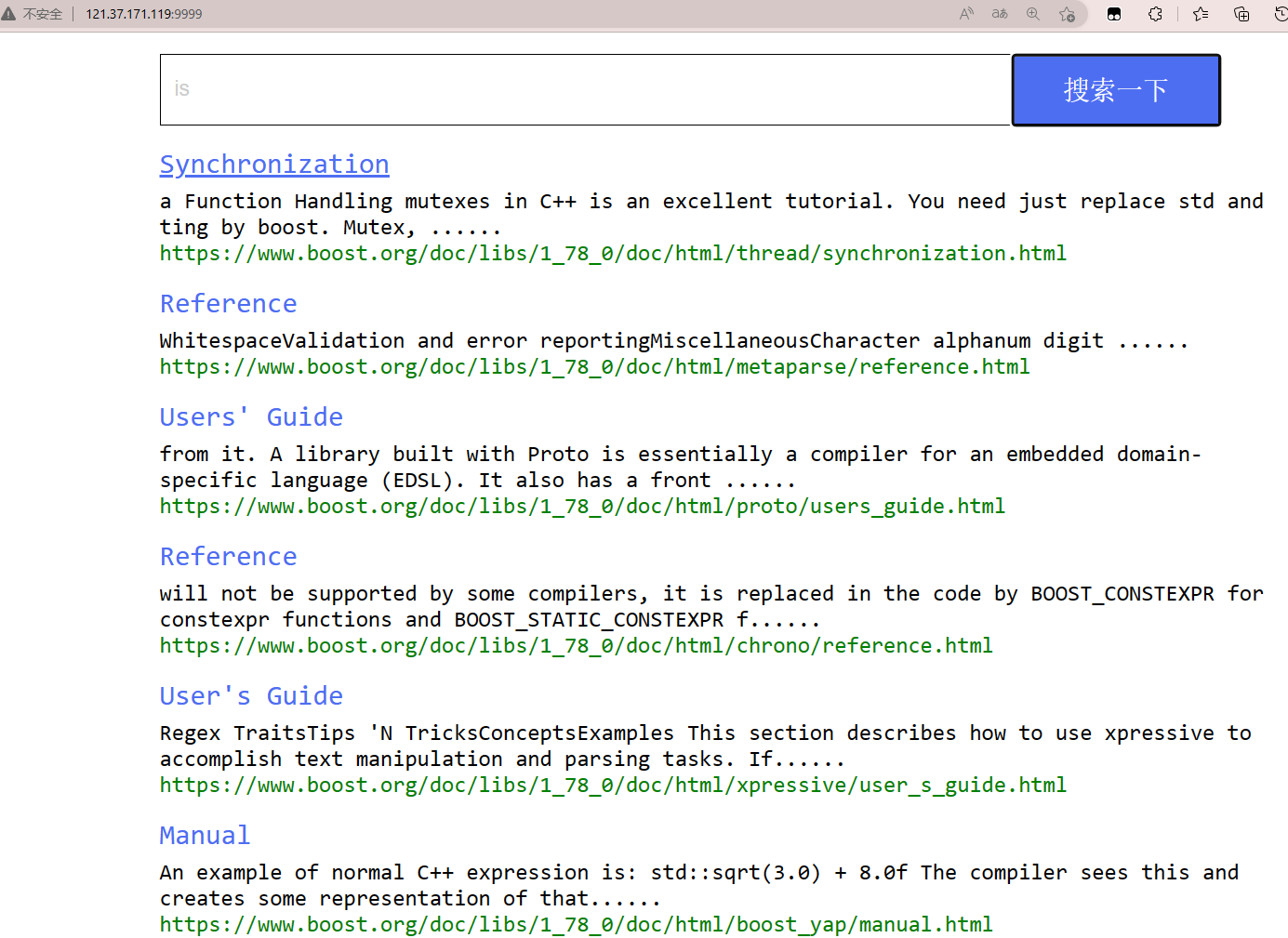
现在我们的搜索引擎,如果搜索一些暂停词,也是可以搜索出结果的
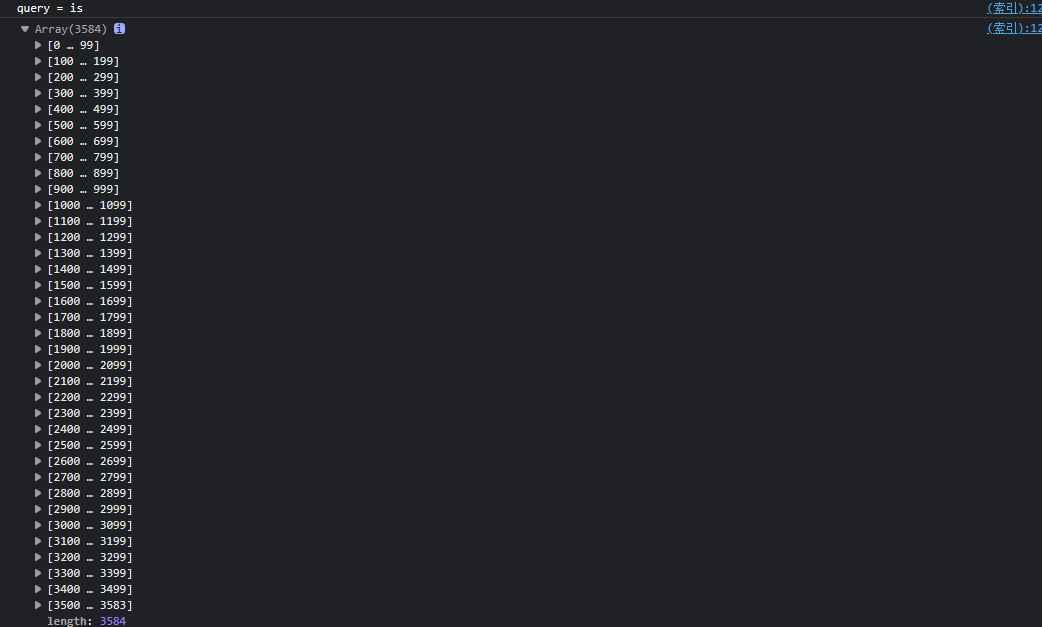
比如我们搜索is,我们知道这种暂停出场频率太高了,如果我们把这些词也作为关键词,那么搜索的时候区分唯一性的价值不大,而且会增加我们建立索引的成本,从而增加我们搜索的成本
可以看到我们以is作为关键词进行搜索的话,我们可以搜索到3000多个文档
当我们去掉暂停词之后,我们再次搜索is
可以看到如下的效果,什么也搜索不到
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。