

代码拉取完成,页面将自动刷新
| language | datasets | license | thumbnail | tags | ||
|---|---|---|---|---|---|---|
de |
|
mit |
https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg |
|

Language model: gelectra-base-germanquad
Language: German
Training data: GermanQuAD train set (~ 12MB)
Eval data: GermanQuAD test set (~ 5MB)
Infrastructure: 1x V100 GPU
Published: Apr 21st, 2021
See https://deepset.ai/germanquad for more details and dataset download in SQuAD format.
batch_size = 24
n_epochs = 2
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
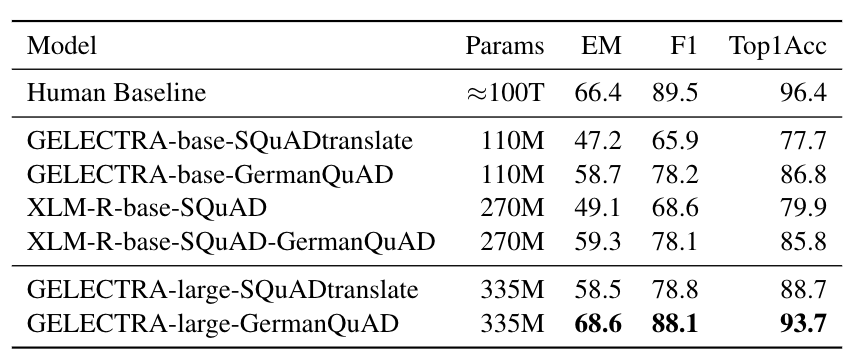
We evaluated the extractive question answering performance on our GermanQuAD test set.
Model types and training data are included in the model name.
For finetuning XLM-Roberta, we use the English SQuAD v2.0 dataset.
The GELECTRA models are warm started on the German translation of SQuAD v1.1 and finetuned on GermanQuAD.
The human baseline was computed for the 3-way test set by taking one answer as prediction and the other two as ground truth.
Timo Möller: timo.moeller@deepset.ai
Julian Risch: julian.risch@deepset.ai
Malte Pietsch: malte.pietsch@deepset.ai
deepset is the company behind the open-source NLP framework Haystack which is designed to help you build production ready NLP systems that use: Question answering, summarization, ranking etc.
Some of our other work:
For more info on Haystack, visit our GitHub repo and Documentation.
We also have a Discord community open to everyone!
Twitter | LinkedIn | Discord | GitHub Discussions | Website
By the way: we're hiring!
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。
1. 开源生态
2. 协作、人、软件
3. 评估模型







