

代码拉取完成,页面将自动刷新
| language | license | thumbnail | tags | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
de |
mit |
https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png |
|
We released an improved version of this model. Version 1 was trained for 766,000 steps. For this new version we continued the training for an additional 734,000 steps. It therefore follows that version 2 was trained on a total of 1,500,000 steps. See "Evaluation of Version 2: GermEval18 Coarse" below for details.
This Model is suitable for training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).
It can be used as a drop-in replacement for BERT in most down-stream tasks (ELECTRA is even implemented as an extended BERT Class).
At the time of release (August 2020) this model is the best performing publicly available German NLP model on various German evaluation metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.
This model has the special feature that it is uncased but does not strip accents. This possibility was added by us with PR #6280. To use it you have to use Transformers version 3.1.0 or newer.
pip install transformers -U
This model is uncased. This helps especially for domains where colloquial terms with uncorrect capitalization is often used.
The special characters 'ö', 'ü', 'ä' are included through the strip_accent=False option, as this leads to an improved precision.
This model was trained and open sourced in conjunction with the German NLP Group in equal parts by:
We evaluated all language models on GermEval18 with the F1 macro score. For each model we did an extensive automated hyperparameter search. With the best hyperparmeters we did fit the moodel multiple times on GermEval18. This is done to cancel random effects and get results of statistical relevance.
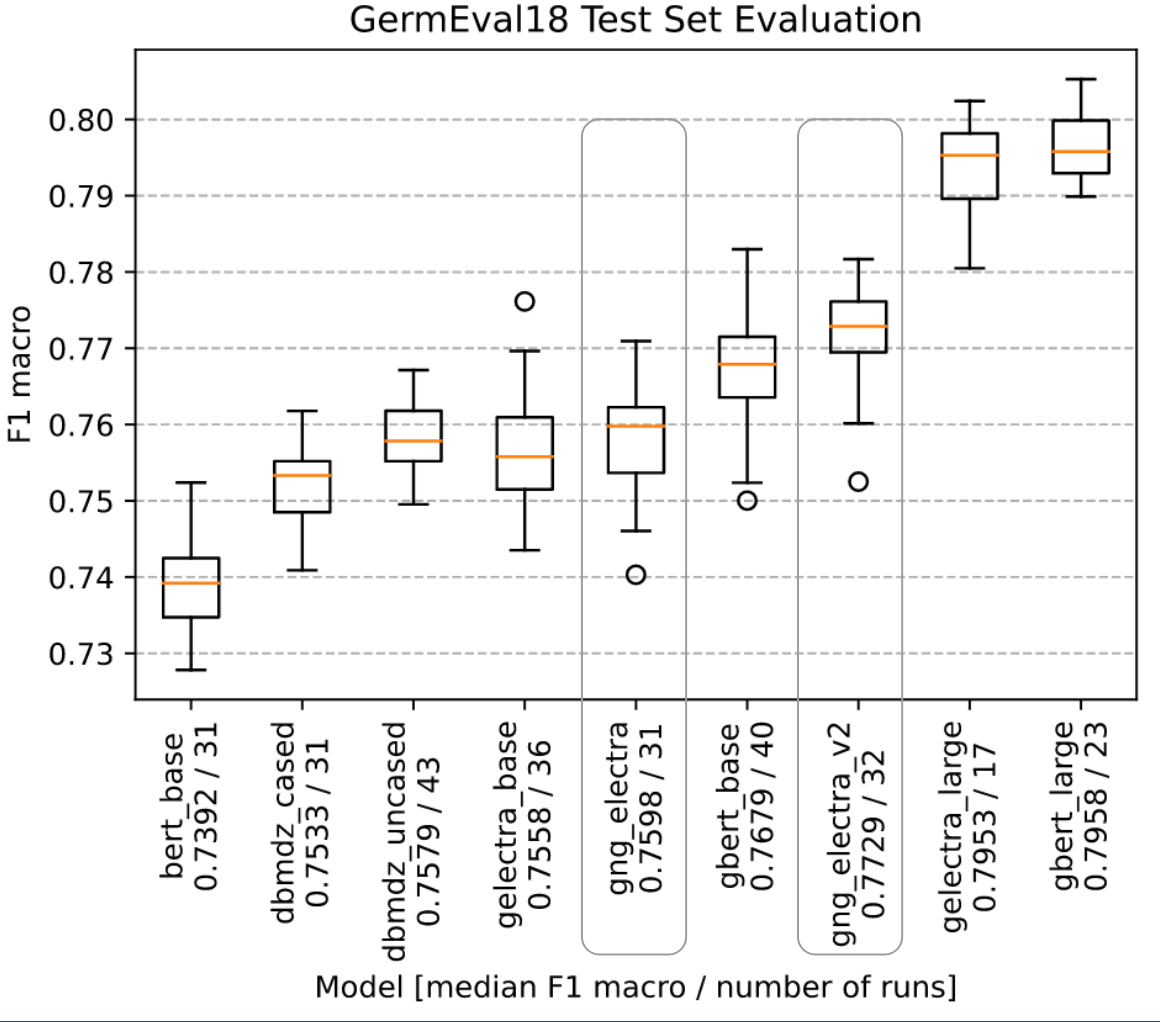
Since it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus.
The sentences were split with SojaMo. We took the German Wikipedia Article Pages Dump 3x to oversample. This approach was also used in a similar way in GPT-3 (Table 2.2).
More Details can be found here Preperaing Datasets for German Electra Github
Because we do not want to stip accents in our training data we made a change to Electra and used this repo Electra no_strip_accents (branch no_strip_accents). Then created the tf dataset with:
python build_pretraining_dataset.py --corpus-dir <corpus_dir> --vocab-file <dir>/vocab.txt --output-dir ./tf_data --max-seq-length 512 --num-processes 8 --do-lower-case --no-strip-accents
The training itself can be performed with the Original Electra Repo (No special case for this needed). We run it with the following Config:
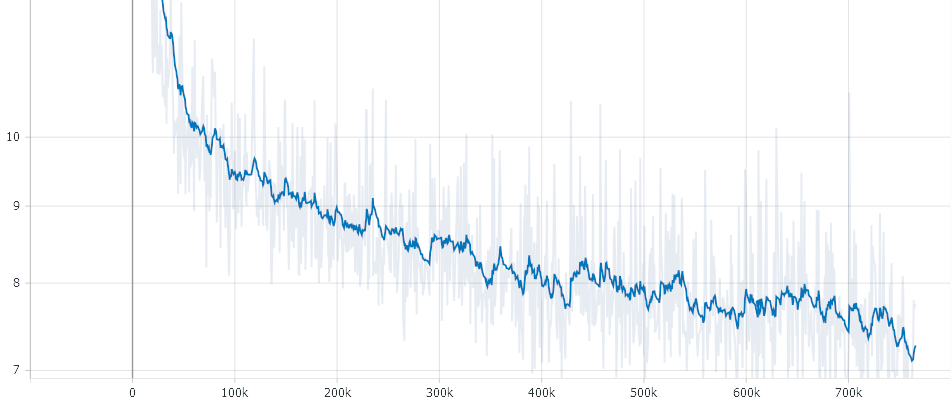
Please Note: Due to the GAN like strucutre of Electra the loss is not that meaningful
It took about 7 Days on a preemtible TPU V3-8. In total, the Model went through approximately 10 Epochs. For an automatically recreation of a cancelled TPUs we used tpunicorn. The total cost of training summed up to about 450 $ for one run. The Data-pre processing and Vocab Creation needed approximately 500-1000 CPU hours. Servers were fully provided by T-Systems on site services GmbH, ambeRoad. Special thanks to Stefan Schweter for your feedback and providing parts of the text corpus.
[¹]: Source for the picture Pinterest
We tried the following approaches which we found had no positive influence:
Copyright 2020-2021 Philip May
Copyright 2020-2021 Philipp Reißel
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。
1. 开源生态
2. 协作、人、软件
3. 评估模型







