

代码拉取完成,页面将自动刷新
| title | category | tag | |
|---|---|---|---|
Disruptor常见问题总结 |
高性能 |
|
Disruptor 是一个相对冷门一些的知识点,不过,如果你的项目经历中用到了 Disruptor 的话,那面试中就很可能会被问到。
一位球友之前投稿的面经(社招)中就涉及一些 Disruptor 的问题,文章传送门:圆梦!顺利拿到字节、淘宝、拼多多等大厂 offer! 。

这篇文章可以看作是对 Disruptor 做的一个简单总结,每个问题都不会扯太深入,主要针对面试或者速览 Disruptor。
Disruptor 是一个开源的高性能内存队列,诞生初衷是为了解决内存队列的性能和内存安全问题,由英国外汇交易公司 LMAX 开发。
根据 Disruptor 官方介绍,基于 Disruptor 开发的系统 LMAX(新的零售金融交易平台),单线程就能支撑每秒 600 万订单。Martin Fowler 在 2011 年写的一篇文章 The LMAX Architecture 中专门介绍过这个 LMAX 系统的架构,感兴趣的可以看看这篇文章。。
LMAX 公司 2010 年在 QCon 演讲后,Disruptor 获得了业界关注,并获得了 2011 年的 Oracle 官方的 Duke's Choice Awards(Duke 选择大奖)。

“Duke 选择大奖”旨在表彰过去一年里全球个人或公司开发的、最具影响力的 Java 技术应用,由甲骨文公司主办。含金量非常高!
我专门找到了 Oracle 官方当年颁布获得 Duke's Choice Awards 项目的那篇文章(文章地址:https://blogs.oracle.com/java/post/and-the-winners-arethe-dukes-choice-award) 。从文中可以看出,同年获得此大奖荣誉的还有大名鼎鼎的 Netty、JRebel 等项目。
Disruptor 提供的功能优点类似于 Kafka、RocketMQ 这类分布式队列,不过,其作为范围是 JVM(内存)。
关于如何在 Spring Boot 项目中使用 Disruptor,可以看这篇文章:Spring Boot + Disruptor 实战入门 。
Disruptor 主要解决了 JDK 内置线程安全队列的性能和内存安全问题。
JDK 中常见的线程安全的队列如下:
| 队列名字 | 锁 | 是否有界 |
|---|---|---|
ArrayBlockingQueue |
加锁(ReentrantLock) |
有界 |
LinkedBlockingQueue |
加锁(ReentrantLock) |
有界 |
LinkedTransferQueue |
无锁(CAS) |
无界 |
ConcurrentLinkedQueue |
无锁(CAS) |
无界 |
从上表中可以看出:这些队列要不就是加锁有界,要不就是无锁无界。而加锁的的队列势必会影响性能,无界的队列又存在内存溢出的风险。
因此,一般情况下,我们都是不建议使用 JDK 内置线程安全队列。
Disruptor 就不一样了!它在无锁的情况下还能保证队列有界,并且还是线程安全的。
下面这张图是 Disruptor 官网提供的 Disruptor 和 ArrayBlockingQueue 的延迟直方图对比。
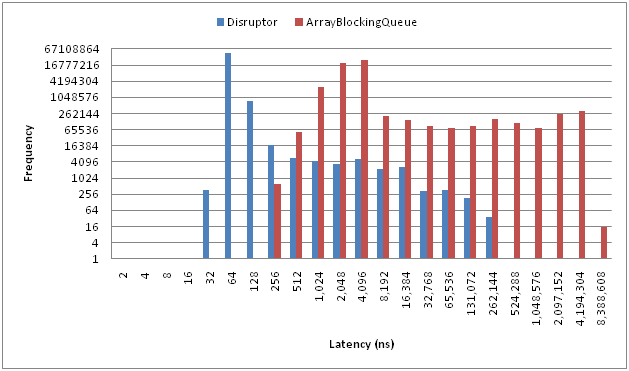
Disruptor 真的很快,关于它为什么这么快这个问题,会在后文介绍到。
此外,Disruptor 还提供了丰富的扩展功能比如支持批量操作、支持多种等待策略。
用到 Disruptor 的开源项目还是挺多的,这里简单举几个例子:
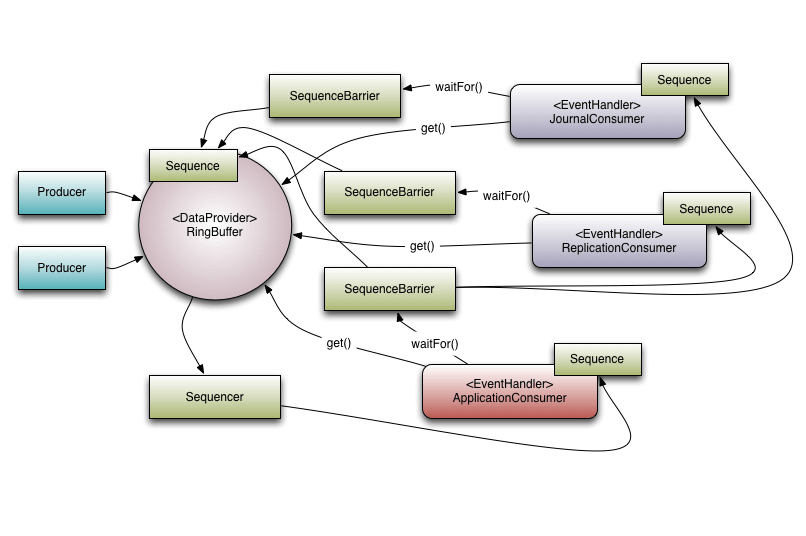
Disruptor 类的时候需要用到。Disruptor 对象。Disruptor 对象发布事件的用户代码,Disruptor 没有定义特定接口或类型。SingleProducerSequencer、MultiProducerSequencer ,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。下面这张图摘自 Disruptor 官网,展示了 LMAX 系统使用 Disruptor 的示例。
等待策略(WaitStrategy) 决定了没有事件可以消费的时候,事件消费者如何等待新事件的到来。
常见的等待策略有下面这些:

BlockingWaitStrategy:基于 ReentrantLock+Condition 来实现等待和唤醒操作,实现代码非常简单,是 Disruptor 默认的等待策略。虽然最慢,但也是 CPU 使用率最低和最稳定的选项生产环境推荐使用;BusySpinWaitStrategy:性能很好,存在持续自旋的风险,使用不当会造成 CPU 负载 100%,慎用;LiteBlockingWaitStrategy:基于 BlockingWaitStrategy 的轻量级等待策略,在没有锁竞争的时候会省去唤醒操作,但是作者说测试不充分,因此不建议使用;TimeoutBlockingWaitStrategy:带超时的等待策略,超时后会执行业务指定的处理逻辑;LiteTimeoutBlockingWaitStrategy:基于TimeoutBlockingWaitStrategy的策略,当没有锁竞争的时候会省去唤醒操作;SleepingWaitStrategy:三段式策略,第一阶段自旋,第二阶段执行 Thread.yield 让出 CPU,第三阶段睡眠执行时间,反复的睡眠;YieldingWaitStrategy:二段式策略,第一阶段自旋,第二阶段执行 Thread.yield 交出 CPU;PhasedBackoffWaitStrategy:四段式策略,第一阶段自旋指定次数,第二阶段自旋指定时间,第三阶段执行 Thread.yield 交出 CPU,第四阶段调用成员变量的waitFor方法,该成员变量可以被设置为BlockingWaitStrategy、LiteBlockingWaitStrategy、SleepingWaitStrategy三个中的一个。综上所述,Disruptor 之所以能够如此快,是基于一系列优化策略的综合作用,既充分利用了现代 CPU 缓存结构的特点,又避免了常见的并发问题和性能瓶颈。
关于 Disruptor 高性能队列原理的详细介绍,可以查看这篇文章:Disruptor 高性能队列原理浅析 (参考了美团技术团队的高性能队列——Disruptor这篇文章)。
🌈 这里额外补充一点:数组中对象元素地址连续为什么可以提高性能?
CPU 缓存是通过将最近使用的数据存储在高速缓存中来实现更快的读取速度,并使用预取机制提前加载相邻内存的数据以利用局部性原理。
在计算机系统中,CPU 主要访问高速缓存和内存。高速缓存是一种速度非常快、容量相对较小的内存,通常被分为多级缓存,其中 L1、L2、L3 分别表示一级缓存、二级缓存、三级缓存。越靠近 CPU 的缓存,速度越快,容量也越小。相比之下,内存容量相对较大,但速度较慢。
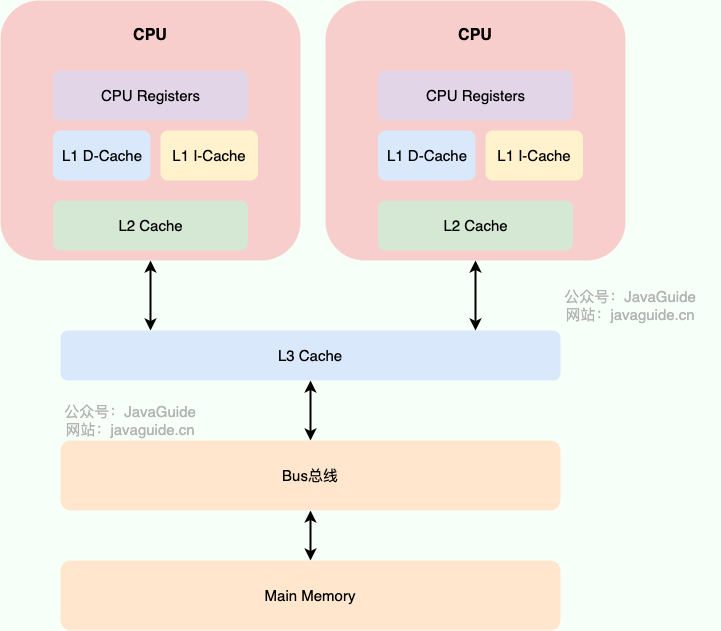
为了加速数据的读取过程,CPU 会先将数据从内存中加载到高速缓存中,如果下一次需要访问相同的数据,就可以直接从高速缓存中读取,而不需要再次访问内存。这就是所谓的 缓存命中 。另外,为了利用 局部性原理 ,CPU 还会根据之前访问的内存地址预取相邻的内存数据,因为在程序中,连续的内存地址通常会被频繁访问到,这样做可以提高数据的缓存命中率,进而提高程序的性能。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。






