

Fetch the repository succeeded.
| title | category | tag | |
|---|---|---|---|
计算机网络常见面试题总结(上) |
计算机基础 |
|
上篇主要是计算机网络基础和应用层相关的内容。
OSI 七层模型 是国际标准化组织提出的一个网络分层模型,其大体结构以及每一层提供的功能如下图所示:
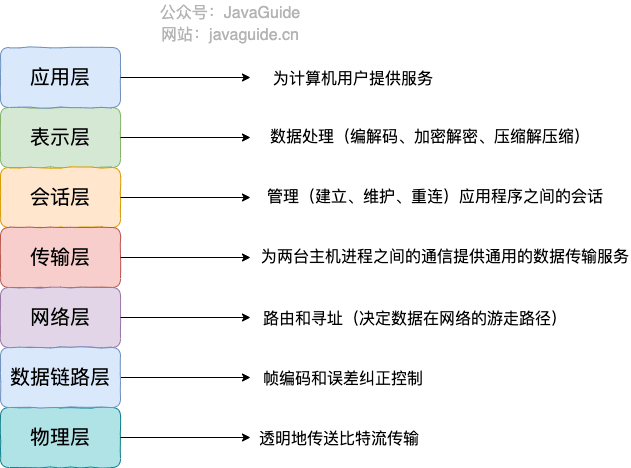
每一层都专注做一件事情,并且每一层都需要使用下一层提供的功能比如传输层需要使用网络层提供的路由和寻址功能,这样传输层才知道把数据传输到哪里去。
OSI 的七层体系结构概念清楚,理论也很完整,但是它比较复杂而且不实用,而且有些功能在多个层中重复出现。
上面这种图可能比较抽象,再来一个比较生动的图片。下面这个图片是我在国外的一个网站上看到的,非常赞!
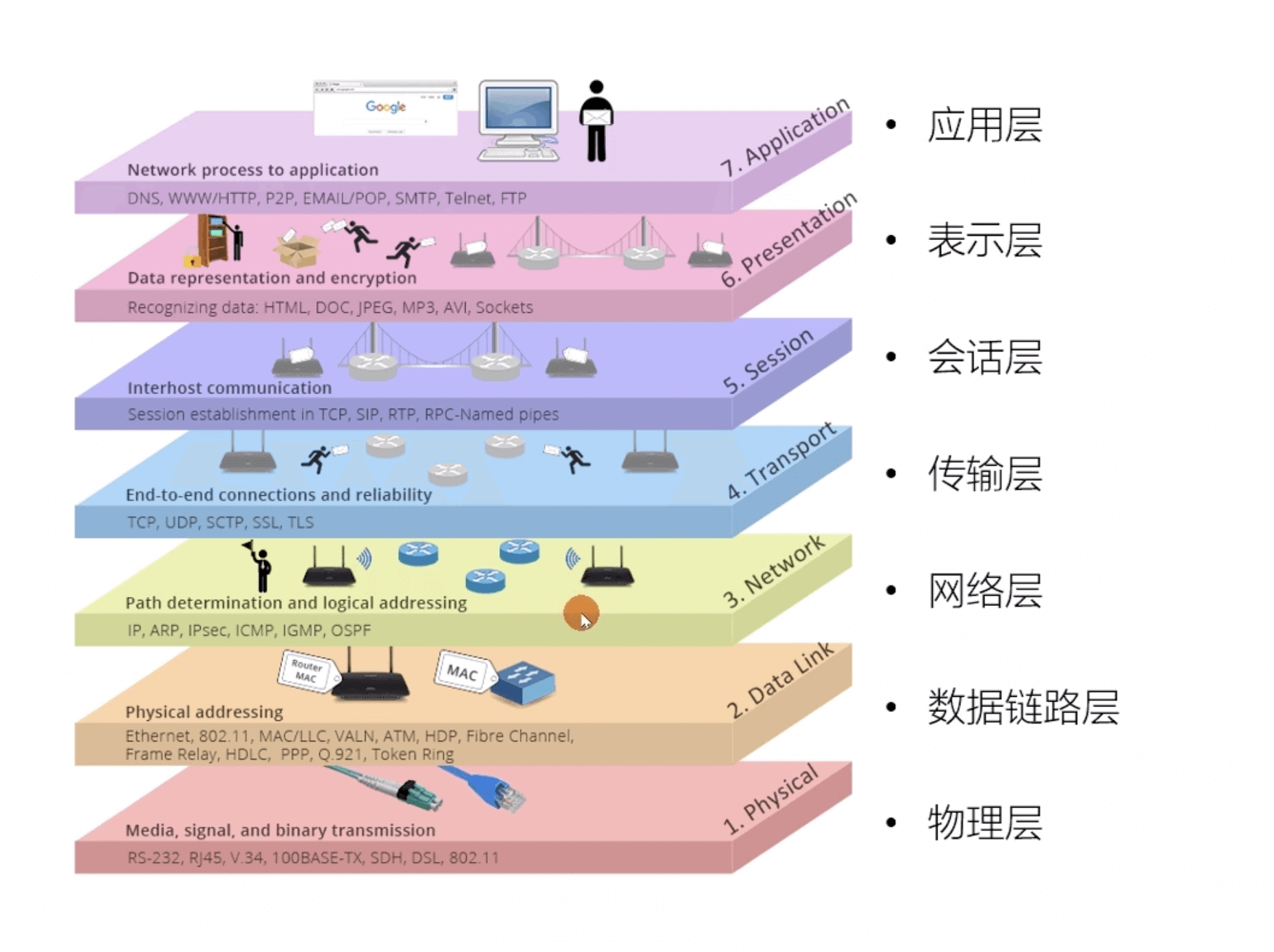
TCP/IP 四层模型 是目前被广泛采用的一种模型,我们可以将 TCP / IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
需要注意的是,我们并不能将 TCP/IP 四层模型 和 OSI 七层模型完全精确地匹配起来,不过可以简单将两者对应起来,如下图所示:

关于每一层作用的详细介绍,请看 OSI 和 TCP/IP 网络分层模型详解(基础) 这篇文章。
说到分层,我们先从我们平时使用框架开发一个后台程序来说,我们往往会按照每一层做不同的事情的原则将系统分为三层(复杂的系统分层会更多):
复杂的系统需要分层,因为每一层都需要专注于一类事情。网络分层的原因也是一样,每一层只专注于做一类事情。
好了,再来说回:“为什么网络要分层?”。我觉得主要有 3 方面的原因:
我想到了计算机世界非常非常有名的一句话,这里分享一下:
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决,计算机整个体系从上到下都是按照严格的层次结构设计的。
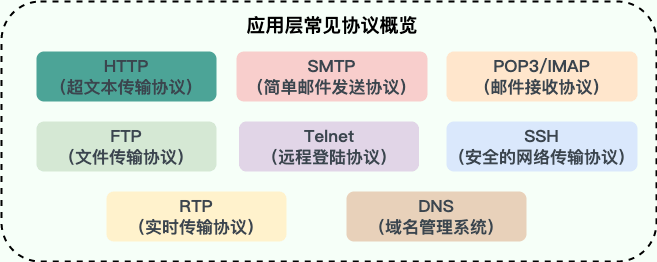
关于这些协议的详细介绍请看 应用层常见协议总结(应用层) 这篇文章。


类似的问题:打开一个网页,整个过程会使用哪些协议?
先来看一张图(来源于《图解 HTTP》):
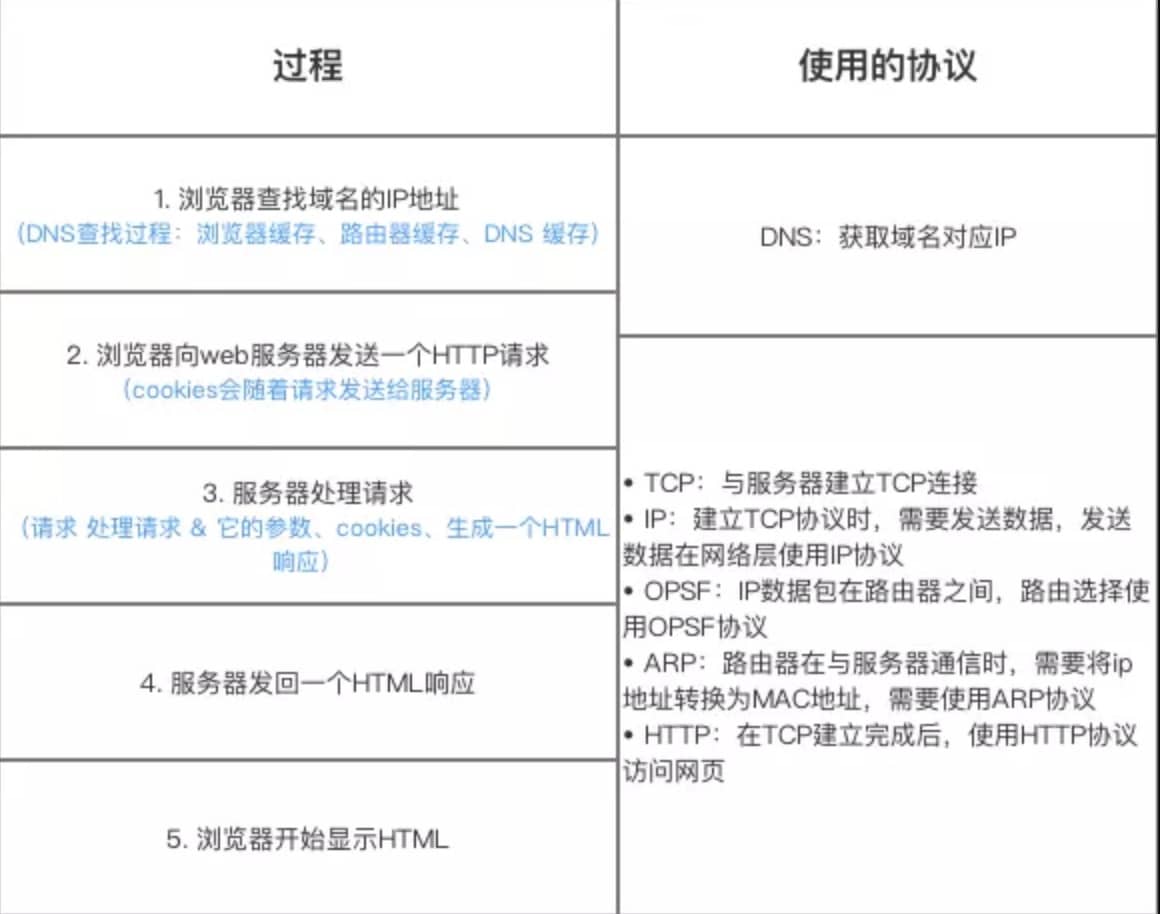
上图有一个错误需要注意:是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
总体来说分为以下几个步骤:
详细介绍可以查看这篇文章:访问网页的全过程(知识串联)(强烈推荐)。
HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。
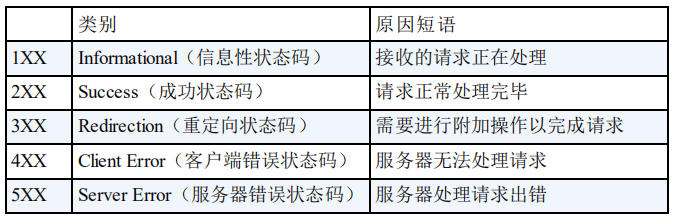
关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:HTTP 常见状态码总结(应用层)。
| 请求头字段名 | 说明 | 示例 |
|---|---|---|
| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
| Accept-Encoding | 能够接受的编码方式列表。参考 HTTP 压缩。 | Accept-Encoding: gzip, deflate |
| Accept-Language | 能够接受的回应内容的自然语言列表。 | Accept-Language: en-US |
| Authorization | 用于超文本传输协议的认证的认证信息 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Cache-Control | 用来指定在这次的请求/响应链中的所有缓存机制 都必须 遵守的指令 | Cache-Control: no-cache |
| Connection | 该浏览器想要优先使用的连接类型 | Connection: keep-alive Connection: Upgrade |
| Content-Length | 以 八位字节数组 (8 位的字节)表示的请求体的长度 | Content-Length: 348 |
| Content-MD5 | 请求体的内容的二进制 MD5 散列值,以 Base64 编码的结果 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
| Content-Type | 请求体的 多媒体类型 (用于 POST 和 PUT 请求中) | Content-Type: application/x-www-form-urlencoded |
| Cookie | 之前由服务器通过 Set- Cookie (下文详述)发送的一个 超文本传输协议 Cookie | Cookie: $Version=1; Skin=new; |
| Date | 发送该消息的日期和时间(按照 RFC 7231 中定义的"超文本传输协议日期"格式来发送) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
| Expect | 表明客户端要求服务器做出特定的行为 | Expect: 100-continue |
| From | 发起此请求的用户的邮件地址 | From: user@example.com |
| Host | 服务器的域名(用于虚拟主机 ),以及服务器所监听的传输控制协议端口号。如果所请求的端口是对应的服务的标准端口,则端口号可被省略。 | Host: en.wikipedia.org:80 |
| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要作用时,用作像 PUT 这样的方法中,仅当从用户上次更新某个资源以来,该资源未被修改的情况下,才更新该资源。 | If-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Modified-Since | 允许在对应的内容未被修改的情况下返回 304 未修改( 304 Not Modified ) | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
| If-None-Match | 允许在对应的内容未被修改的情况下返回 304 未修改( 304 Not Modified ) | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Range | 如果该实体未被修改过,则向我发送我所缺少的那一个或多个部分;否则,发送整个新的实体 | If-Range: “737060cd8c284d8af7ad3082f209582d” |
| If-Unmodified-Since | 仅当该实体自某个特定时间已来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 |
| Origin | 发起一个针对 跨来源资源共享 的请求。 | Origin: http://www.example-social-network.com |
| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生多种效果。 | Pragma: no-cache |
| Proxy-Authorization | 用来向代理进行认证的认证信息。 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Range | 仅请求某个实体的一部分。字节偏移以 0 开始。参见字节服务。 | Range: bytes=500-999 |
| Referer | 表示浏览器所访问的前一个页面,正是那个页面上的某个链接将浏览器带到了当前所请求的这个页面。 | Referer: http://en.wikipedia.org/wiki/Main_Page |
| TE | 浏览器预期接受的传输编码方式:可使用回应协议头 Transfer-Encoding 字段中的值; | TE: trailers, deflate |
| Upgrade | 要求服务器升级到另一个协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent | 浏览器的浏览器身份标识字符串 | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
| Via | 向服务器告知,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
| Warning | 一个一般性的警告,告知,在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning |

http://,HTTPS 的 URL 前缀是 https://。关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:HTTP vs HTTPS(应用层) 。

100 (Continue)——在请求大资源前的预热请求,206 (Partial Content)——范围请求的标识码,409 (Conflict)——请求与当前资源的规定冲突,410 (Gone)——资源已被永久转移,而且没有任何已知的转发地址。关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:HTTP/1.0 vs HTTP/1.1(应用层) 。

Body压缩,Header不支持压缩。HTTP/2.0 支持对Header压缩,使用了专门为Header压缩而设计的 HPACK 算法,减少了网络开销。HTTP/2.0 多路复用效果图(图源: HTTP/2 For Web Developers):
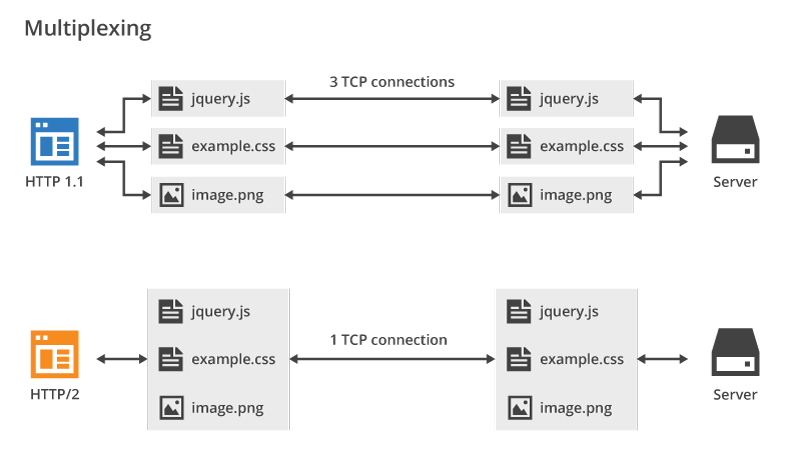
可以看到,HTTP/2.0 的多路复用使得不同的请求可以共用一个 TCP 连接,避免建立多个连接带来不必要的额外开销,而 HTTP/1.1 中的每个请求都会建立一个单独的连接

HTTP/1.0、HTTP/2.0 和 HTTP/3.0 的协议栈比较:

关于 HTTP/1.0 -> HTTP/3.0 更详细的演进介绍,推荐阅读HTTP1 到 HTTP3 的工程优化。
HTTP 是一种不保存状态,即无状态(stateless)协议。也就是说 HTTP 协议自身不对请求和响应之间的通信状态进行保存。那么我们如何保存用户状态呢?Session 机制的存在就是为了解决这个问题,Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个 Session)。
在服务端保存 Session 的方法很多,最常用的就是内存和数据库(比如是使用内存数据库 redis 保存)。既然 Session 存放在服务器端,那么我们如何实现 Session 跟踪呢?大部分情况下,我们都是通过在 Cookie 中附加一个 Session ID 来方式来跟踪。
Cookie 被禁用怎么办?
最常用的就是利用 URL 重写把 Session ID 直接附加在 URL 路径的后面。
URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL 是一种具体的 URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
准确点来说,这个问题属于认证授权的范畴,你可以在 认证授权基础概念详解 这篇文章中找到详细的答案。
这个问题在知乎上被讨论的挺火热的,地址:https://www.zhihu.com/question/28586791 。
GET 和 POST 是 HTTP 协议中两种常用的请求方法,它们在不同的场景和目的下有不同的特点和用法。一般来说,可以从以下几个方面来区分二者(重点搞清两者在语义上的区别即可):
再次提示,重点搞清两者在语义上的区别即可,实际使用过程中,也是通过语义来区分使用 GET 还是 POST。不过,也有一些项目所有的请求都用 POST,这个并不是固定的,项目组达成共识即可。
WebSocket 是一种基于 TCP 连接的全双工通信协议,即客户端和服务器可以同时发送和接收数据。
WebSocket 协议在 2008 年诞生,2011 年成为国际标准,几乎所有主流较新版本的浏览器都支持该协议。不过,WebSocket 不只能在基于浏览器的应用程序中使用,很多编程语言、框架和服务器都提供了 WebSocket 支持。
WebSocket 协议本质上是应用层的协议,用于弥补 HTTP 协议在持久通信能力上的不足。客户端和服务器仅需一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。

下面是 WebSocket 的常见应用场景:
WebSocket 和 HTTP 两者都是基于 TCP 的应用层协议,都可以在网络中传输数据。
下面是二者的主要区别:
WebSocket 的工作过程可以分为以下几个步骤:
Upgrade: websocket 和 Sec-WebSocket-Key 等字段,表示要求升级协议为 WebSocket;Connection: Upgrade和 Sec-WebSocket-Accept: xxx 等字段、表示成功升级到 WebSocket 协议。另外,建立 WebSocket 连接之后,通过心跳机制来保持 WebSocket 连接的稳定性和活跃性。
摘自Web 实时消息推送详解。
SSE 与 WebSocket 作用相似,都可以建立服务端与浏览器之间的通信,实现服务端向客户端推送消息,但还是有些许不同:
SSE 与 WebSocket 该如何选择?
SSE 好像一直不被大家所熟知,一部分原因是出现了 WebSocket,这个提供了更丰富的协议来执行双向、全双工通信。对于游戏、即时通信以及需要双向近乎实时更新的场景,拥有双向通道更具吸引力。
但是,在某些情况下,不需要从客户端发送数据。而你只需要一些服务器操作的更新。比如:站内信、未读消息数、状态更新、股票行情、监控数量等场景,SEE 不管是从实现的难易和成本上都更加有优势。此外,SSE 具有 WebSocket 在设计上缺乏的多种功能,例如:自动重新连接、事件 ID 和发送任意事件的能力。
PING 命令是一种常用的网络诊断工具,经常用来测试网络中主机之间的连通性和网络延迟。
这里简单举一个例子,我们来 PING 一下百度。
# 发送4个PING请求数据包到 www.baidu.com
❯ ping -c 4 www.baidu.com
PING www.a.shifen.com (14.119.104.189): 56 data bytes
64 bytes from 14.119.104.189: icmp_seq=0 ttl=54 time=27.867 ms
64 bytes from 14.119.104.189: icmp_seq=1 ttl=54 time=28.732 ms
64 bytes from 14.119.104.189: icmp_seq=2 ttl=54 time=27.571 ms
64 bytes from 14.119.104.189: icmp_seq=3 ttl=54 time=27.581 ms
--- www.a.shifen.com ping statistics ---
4 packets transmitted, 4 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 27.571/27.938/28.732/0.474 ms
PING 命令的输出结果通常包括以下几部分信息:
如果 PING 对应的目标主机无法得到正确的响应,则表明这两个主机之间的连通性存在问题(有些主机或网络管理员可能禁用了对 ICMP 请求的回复,这样也会导致无法得到正确的响应)。如果往返时间(RTT)过高,则表明网络延迟过高。
PING 基于网络层的 ICMP(Internet Control Message Protocol,互联网控制报文协议),其主要原理就是通过在网络上发送和接收 ICMP 报文实现的。
ICMP 报文中包含了类型字段,用于标识 ICMP 报文类型。ICMP 报文的类型有很多种,但大致可以分为两类:
PING 用到的 ICMP Echo Request(类型为 8 ) 和 ICMP Echo Reply(类型为 0) 属于查询报文类型 。
DNS(Domain Name System)域名管理系统,是当用户使用浏览器访问网址之后,使用的第一个重要协议。DNS 要解决的是域名和 IP 地址的映射问题。

在一台电脑上,可能存在浏览器 DNS 缓存,操作系统 DNS 缓存,路由器 DNS 缓存。如果以上缓存都查询不到,那么 DNS 就闪亮登场了。
目前 DNS 的设计采用的是分布式、层次数据库结构,DNS 是应用层协议,它可以在 UDP 或 TCP 协议之上运行,端口为 53 。
DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
com、org、net和edu等。国家也有自己的顶级域,如uk、fr和ca。TLD 服务器提供了权威 DNS 服务器的 IP 地址。世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 600 多台,未来还会继续增加。
整个过程的步骤比较多,我单独写了一篇文章详细介绍:DNS 域名系统详解(应用层) 。
DNS 劫持是一种网络攻击,它通过修改 DNS 服务器的解析结果,使用户访问的域名指向错误的 IP 地址,从而导致用户无法访问正常的网站,或者被引导到恶意的网站。DNS 劫持有时也被称为 DNS 重定向、DNS 欺骗或 DNS 污染。DNS 劫持详细介绍可以参考:黑客技术?没你想象的那么难!——DNS 劫持篇。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。






